Quantitative pairwise comparisons
The CRPC protocol is chiefly focused on pairwise comparisons whose results can be measured in a quantitative format—for example, a floating-point number representing the similarity between two pieces of text.
The sections below walk through two concrete examples, derive the general format of a quantitative pairwise comparison, and then extend the idea to networks and adversarial settings.
Example 1: Semantic Textual Similarity (STS)
Semantic Textual Similarity (STS) is a method of determining, regardless of syntax or particular wording, how similar two pieces of written text might be.
Consider the example of @0xsmallbrain ’s natural language prediction market for tomorrow’s headlines: tmr.news .
That site lets users predict the next day’s New York Times headline on a decentralized market, using a cosine similarity algorithm that compares each user’s headline to the actual headline (revealed a day later) to determine payouts.
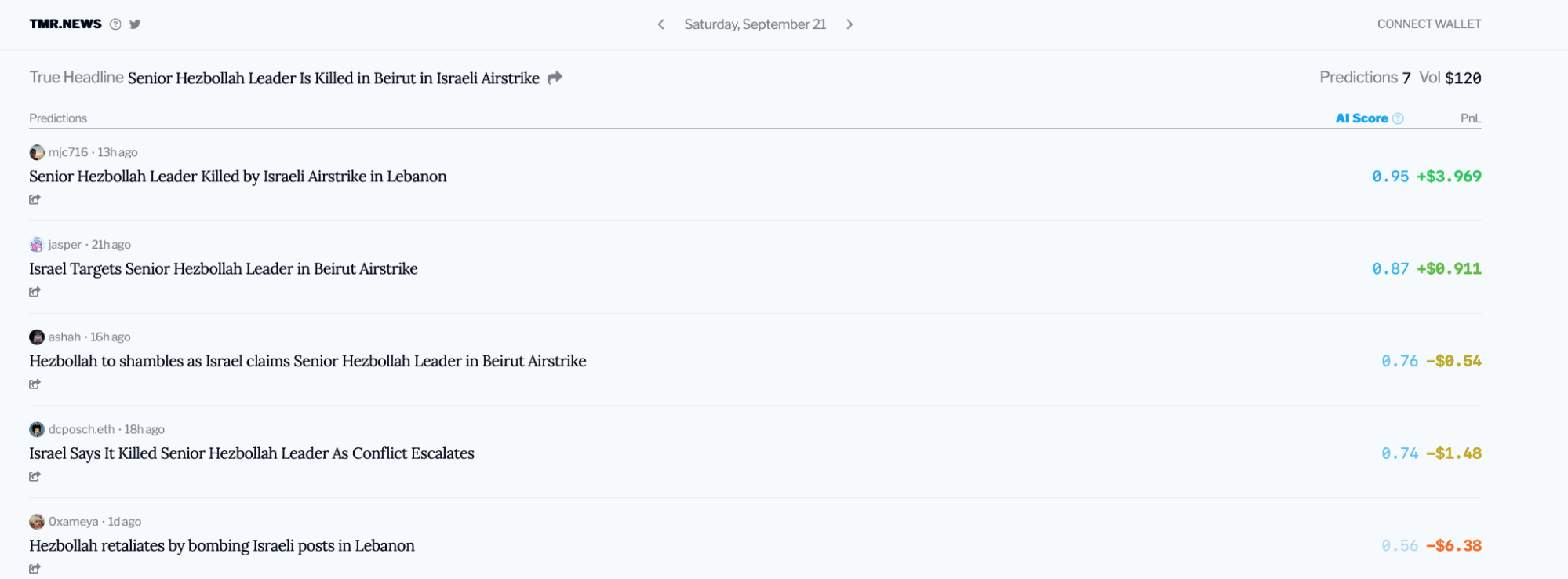
Consider the following headlines and their similarity scores in the prediction market for September 21st, 2024:
- = “Senior Hezbollah Leader is Killed in Beirut in Israeli Airstrike” (actual)
- = “Senior Hezbollah Leader Killed by Israeli Airstrike in Lebanon” (0.95)
- = “Israel Targets Senior Hezbollah Leader in Beirut Airstrike” (0.87)
The site documents that “Scores are calculated using sentence embeddings (sic), specifically using cosine similarity and OpenAI’s text-embeddings-3-large model with dimension 768.”
After each sentence is converted to a vector of embedded tokens (numerical representations) using OpenAI’s text-embeddings-3-large model, cosine similarity is applied to each vector to produce a score between 0 and 1, where 1 means “most alike.”
For reference, a vector of embeddings for begins like: [-0.009729066863656044, 0.010178100317716599, -0.002148742089048028, …].
The usual form of the cosine similarity of two vectors A and B is:
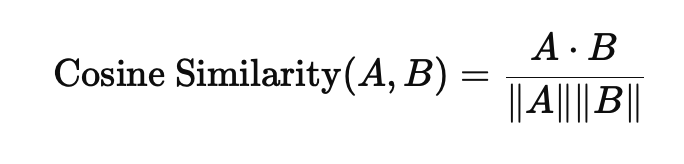
For the headline embeddings , , :
Thus the pairwise comparisons between and , then and , are the cosine similarities of their respective embedding vectors (each a scalar in for comparable, length-normalized embeddings).
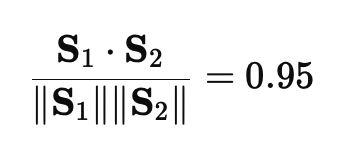
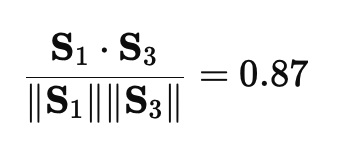
The winner of the prediction market that day was , with a score of 0.95 over the nearest competitor’s 0.87—showing how rich text can still be reduced to a quantitative pairwise comparison.
Note: Cosine similarity for STS does not catch every failure mode—for example, semantic inversions such as “is” vs “isn’t.”
Example 2: Image similarity
Mathematical ways to compare images, such as the Structural Similarity Index (SSIM), are well established.
Suppose a smart contract (an NFT generator for an on-chain game) wants a new potion image. It issues a request to two nodes in a known-good “AI Drawing Service Pool.”
Node A and Node B each render an image from this prompt:
(masterpiece, highest quality), a potion bottle filled with glowing purple liquid, purple theme, video game art, 3D rendering, volumetric lighting, fantasy, simple background
| Node A’s result | Node B’s result |
|---|---|
 |  |
Neither image is identical—we did not fix seeds, steps, or speed optimizations such as xformers—yet either image can be acceptable as a “purple potion” NFT.
A smart contract cannot do a human-like visual review. A numerical pipeline using SSIM (e.g. via oracles) can compare the two renders. SSIM combines luminance (L), contrast (C), and structure (S):
Difference maps can be visualized between images A and B.

For the two acceptable purple potions, SSIM can land near 0.99902838508614.
If one node accidentally used a wrong prompt (e.g. a cached green bottle with ivy), the visuals diverge and SSIM drops—for example to 0.9877919695121076.
Note: You can increase sensitivity (e.g. emphasize structure) by tuning SSIM’s parameter, or by choosing a stronger perceptual similarity metric.
Acceptable error thresholds
The gap between an acceptable score and an unacceptable one can look tiny (here, about 0.011236415574032), but fuzzy or non-deterministic work needs an explicit acceptable error threshold.
Let (epsilon) be that threshold: the comparison difference (delta) should satisfy when similarity is the goal (smaller means “closer match”).
In the purple-potion example, you might set . The between the two good images was 0.00097161491386, which is within the acceptable range.
Example 3: Rolling dice and randomness
You can invert the relationship: require pairwise comparisons to be above a threshold so outputs are sufficiently different. That fits pseudo-randomness for web3 games and autonomous worlds.
Many tools exist (VRFs, MPC, RANDAO, and others). CRPC can still help deliver usable pseudo-random values on demand—for example, within the next block after a request.
A possible Ethereum-shaped sketch:
- Three nodes are tasked with a pseudo-random number in a given range.
- Each node runs a PRNG (e.g. Mersenne Twister) with a seed mixing the block hash and the node id (to discourage caching old useful outputs).
- Each node advances the PRNG state by a fixed number of discarded draws (not wall-clock time), then outputs a value.
- CRPC secures outputs and pairwise comparisons on-chain.
- The contract checks that results differ enough: (pairwise gaps across nodes).
- The contract then selects which node’s value to use (e.g. with the next block hash).
Observers can replay the PRNG steps and report cheating. Because the contract might not pick a lying node’s value, incentives skew toward honesty; full incentive design belongs to a larger consensus layer.
CRPC-style randomness also keeps flexibility in distribution and range—Gaussian vs uniform, and so on—beyond what some VRF / RANDAO-style APIs expose.
General form of pairwise comparisons in a network
Formalize pairwise comparisons on a graph: nodes compute results independently; small differences from noise or benign variation should fall within .
Definitions:
- — the result of a node’s work.
- — the difference between two nodes’ results (how you instantiate this depends on the metric: embedding distance, , etc.).
- — the agreed acceptable error threshold.
Let node produce . The pairwise comparison along an edge between and is . A common choice for scalar outputs is the absolute difference:
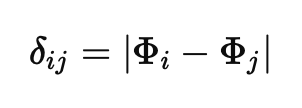
An acceptable comparison (in the “similar enough” regime) satisfies:
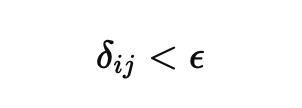
A network of n nodes is a graph with . A directed edge value can be identified with the measured comparison when you use absolute difference on scalars:
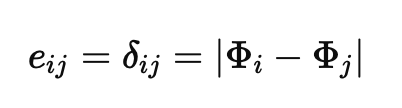
That graph view supports reference pairwise comparisons : the value two honest, faultless nodes would publish on the same edge if they agreed. When reciprocals match, define from the common edge value; otherwise the reference is undefined:
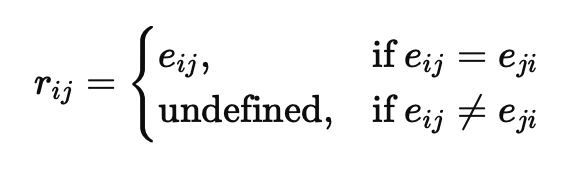
Pairwise comparisons under decentralized conditions
CRPC targets settings where nodes may be faulty or malicious, producing unacceptable comparisons or disagreeing on what the reference comparison along an edge should be.
In decentralization there is no trusted third party that knows the true by inspecting and directly.
Instead, each node compares its output to its neighbor’s. For every undirected edge you get two published comparisons— and —so the requester can validate consistency.
Example setup
Take two nodes and arbitrary work W:
- computes
- computes
- Threshold
- The nodes form a complete graph
We still do not know the “true” for W; we use multiple nodes to test consistency or surface disputes so the requester can decide whom to trust.
From here we can state requirements CRPC must meet to be usefully trust-minimized.
Case 1: Both nodes honest and faultless
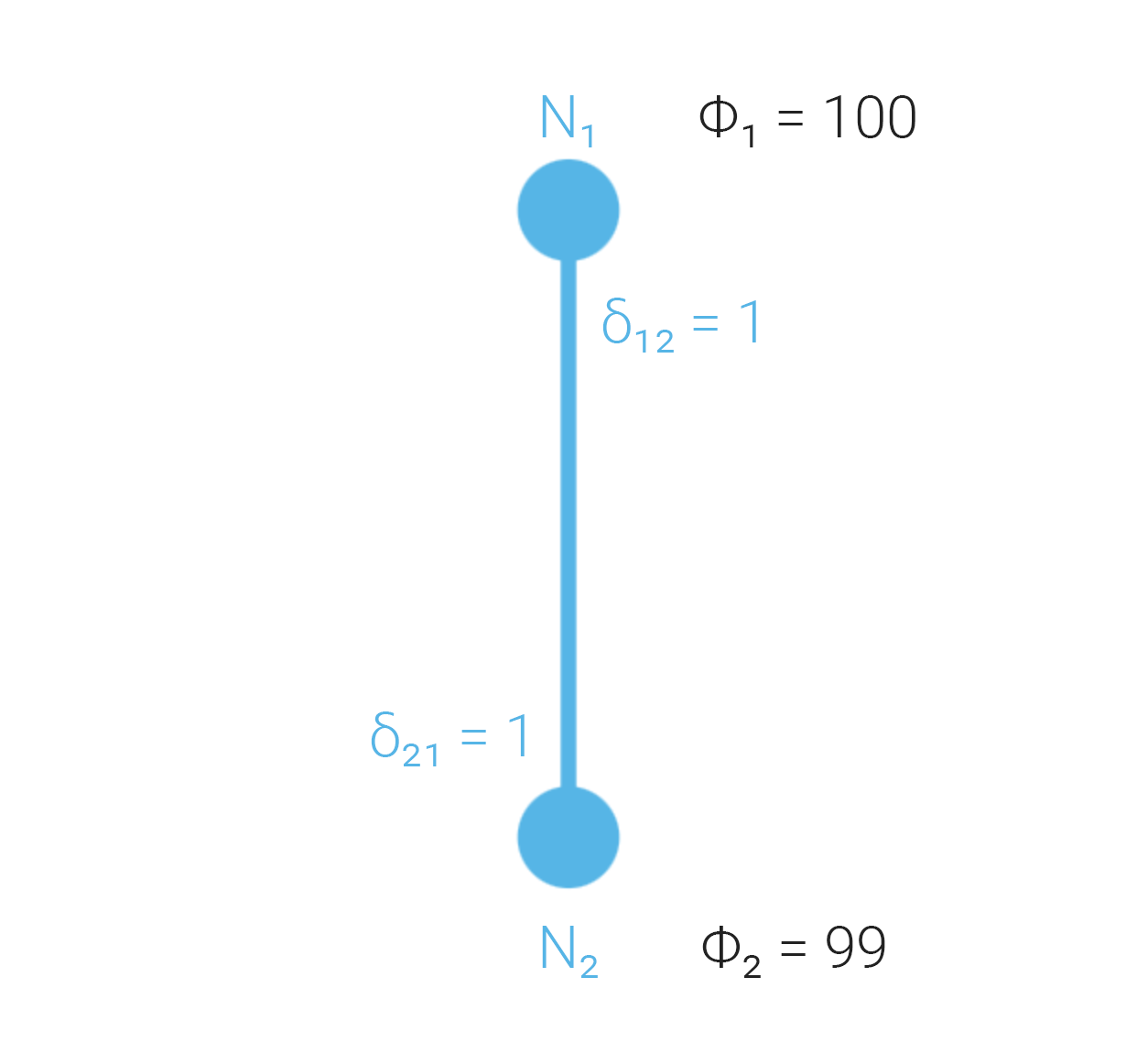
Each node compares honestly; both publish the same edge value, so the mutual reference comparison is (here, ). That mutual agreement supports treating the edge as consistent.
Since (here ), the comparison is acceptable under the threshold—no fault signal from this edge alone.
Note: Both nodes can still be wrong together in a way this edge does not expose; the document discusses that further elsewhere.
Case 2: One node faulty but honest
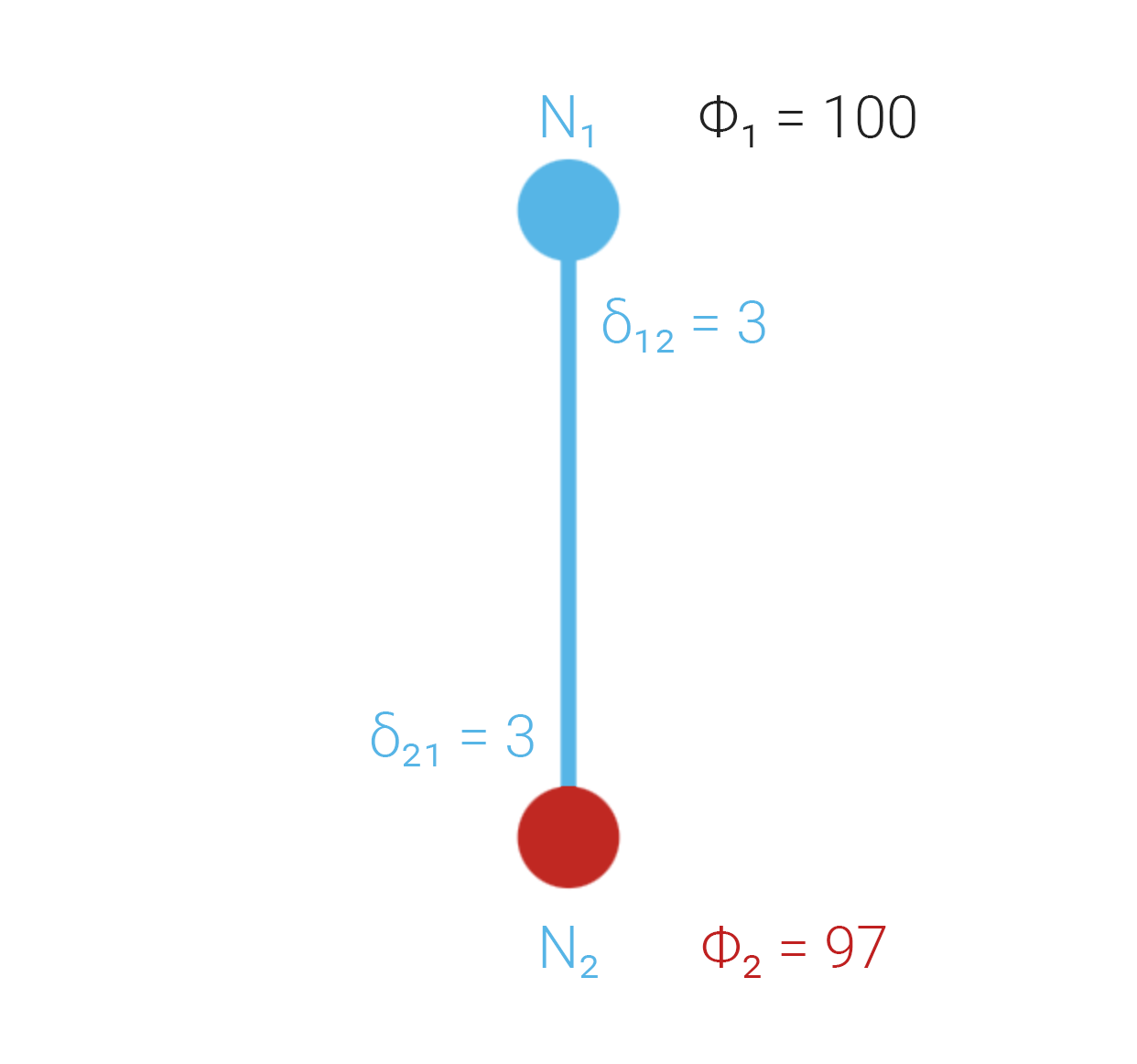
Suppose so while . Honest reporting keeps , so you can compare to .
Because 3 > 2, the requester should not treat the outputs as mutually consistent: there is an active dispute. Resolving it belongs to a mechanism above CRPC (e.g. Byzantine Risk Tolerance, BRT).
Note: With only two nodes you cannot tell which side is wrong; might be the bug. Adding nodes generally improves the chance of catching inconsistencies.
Case 3: One node faulty and dishonest
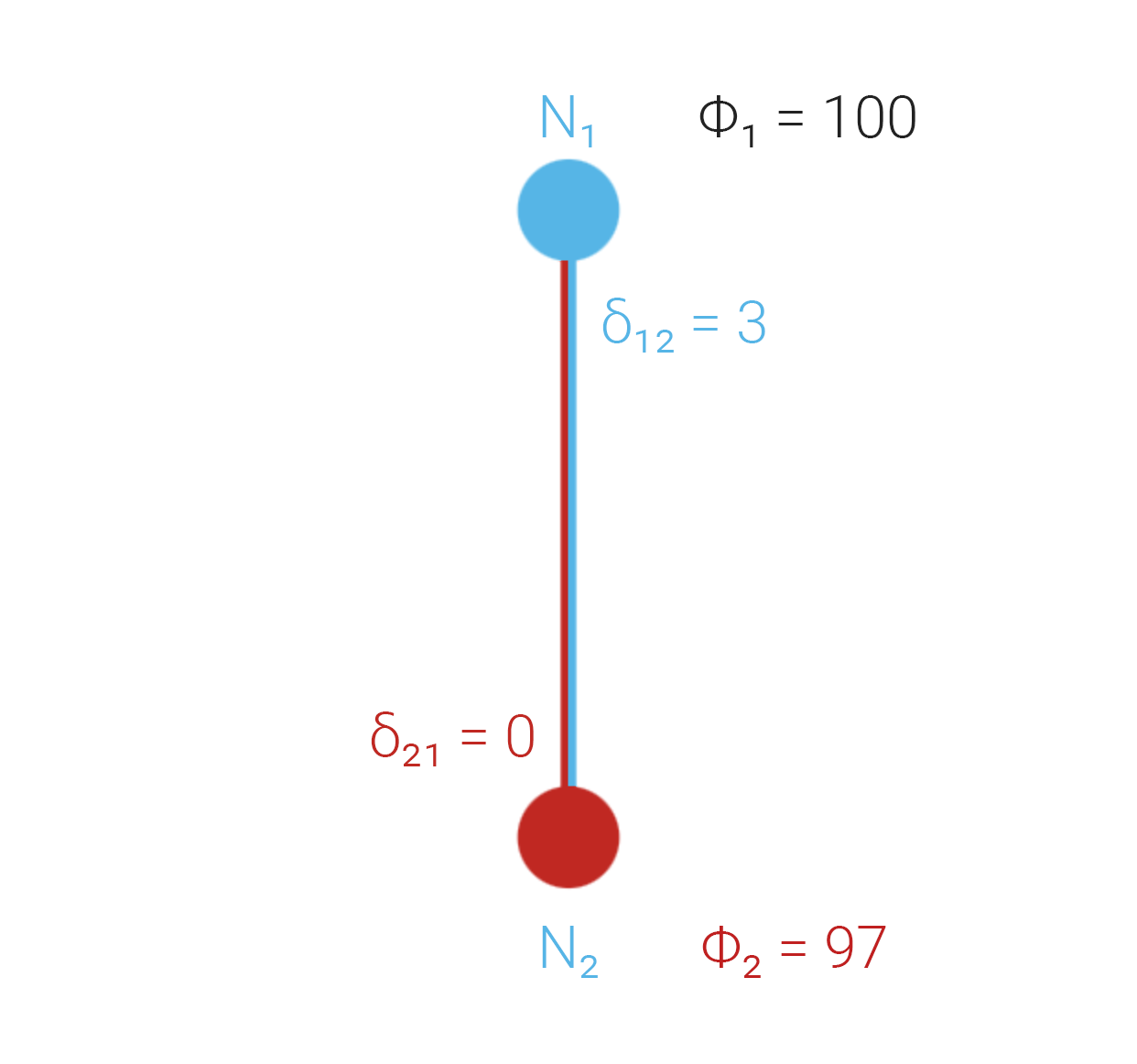
honestly reports 3 between and . lies and broadcasts 0, as if it matched .
When the work itself is too hard to verify directly, the requester leans on pairwise comparison attestations. If only one side ever spoke, the other could lie unchecked.
So both nodes must separately attest to the difference each computed—even when an honest world would make those values equal.
The diagrams below mirror the TikZ cases in the appendix (graphics section).